Perspectives on AI, technology, and compliance transformation to help you move faster, smarter, and with more clarity.

featured insights
ARLINGTON, VA, UNITED STATES, June 9, 2026 -- PhoenixTeam announced the launch of Human Futures, a new initiative helping young people prepare for a world being reshaped by artificial intelligence. Human Futures is grounded in a single belief: the next generation will inherit a different world than the one we grew up in, and it is our responsibility to prepare and employ them. Through AI education, career readiness, employer-connected learning, and hands-on project work, the initiative helps students and early-career professionals develop the skills, confidence, and judgment to use AI thoughtfully, solve real problems, and shape what comes next.
For PhoenixTeam, Human Futures is a natural extension of the company’s work helping organizations understand and apply AI in practical, responsible ways. After years of building AI-enabled solutions, educating mortgage and technology professionals, and helping clients navigate generative AI adoption, PhoenixTeam is now applying that experience to a broader challenge: helping people prepare for the world AI is creating.
The first Human Futures program is underway through PhoenixTeam’s 2026 Summer Internship Program. The cohort includes interns working across Human Futures, AI services and Phoenix Burst, project delivery, business operations, and marketing. Throughout the program, interns receive weekly AI education, learn how businesses operate, build communication and career-readiness skills, and work on individual and team projects that will become part of a real portfolio.
“All of the content we deliver in our Human Futures programming will be accessible to all and available for free. We hope this will be the first of many ways that we can use fear to catalyze action,” said Tela Gallagher Mathias, CTO of PhoenixTeam and CEO of Phoenix Burst. “Human Futures is about bringing the focus back to people. We want young people to understand AI, work with it responsibly, and still build the human skills that make them valuable: courage, judgment, aspiration, resilience, and authentic human connection.”
“The future of work is changing quickly, but preparation cannot just be about tools,” said Tanya Brennan, CEO of PhoenixTeam. “Human Futures is about helping people build the thinking, confidence, and real-world experience they need to participate in that future. The first cohort is already showing what happens when young people are given real problems, real mentors, and room to build.”
Human Futures will continue to grow through programs for students, early-career professionals, educators, families, and employers. The initiative will focus on practical AI readiness, responsible use, portfolio-based learning, and employer-connected pathways that help participants move from learning to contribution.
To learn more, visit www.aifutures.com.
About Human Futures
Human Futures is a PhoenixTeam initiative preparing learners to think, work, and lead in a world being reshaped by artificial intelligence. Built for learners, parents, educators, and employers, Human Futures connects AI education with real-world projects, mentorship, career readiness, and portfolio-based learning. The initiative is rooted in a human-first belief: AI should expand what people are capable of, not replace the thinking, creativity, judgment, and resilience that make people valuable. Through hands-on programs and employer-connected pathways, Human Futures helps learners build practical skills, confidence, and real experience for the future of work and life. For more information, please visit www.aifutures.com
About PhoenixTeam
PhoenixTeam is a woman-owned technology services firm headquartered in Arlington, Virginia, specializing in AI-powered mortgage operations and technology services for the mortgage and financial services industries and federal housing agencies. Our mission is to enable affordable and accessible homeownership through innovative, customer-centric technology. With a strong focus on generative AI, we tackle complex industry challenges, equipping businesses with cutting-edge tools that enhance innovation, efficiency, and compliance. By bridging the gap between technology and business teams, we strive to bring joy and purpose back to software development, making a meaningful impact in the lives of our clients and homeowners everywhere. For more information, please visit www.phoenixoutcomes.com.

featured insights
Phoenix Burst, PhoenixTeam’s AI-powered regulatory intelligence platform, has been recognized as a winner of the MortgagePoint Tech Excellence Award, honoring the most innovative technology providers transforming the mortgage and real estate industries. This marks the second consecutive year Phoenix Burst has received this recognition.
Phoenix Burst was built to simplify how mortgage organizations manage regulatory change. The platform identifies federal and state regulatory updates, creates clear change statements, and produces delivery-ready requirements, user stories, acceptance criteria, and test cases. With guided human review and traceable outputs, Phoenix Burst helps legal, compliance, product, operations, and delivery teams reduce manual effort, standardize interpretation, and move from analysis to implementation faster.
The platform’s design prioritizes both innovation and responsibility. Built-in safeguards including human-in-the-loop curation and retrieval-augmented generation ensure that AI-driven efficiency aligns with compliance requirements and industry standards. Phoenix Burst is also SOC 2 Type II compliant. That standard means an independent auditor tested the platform's data security controls over time and confirmed they operate as intended. For enterprise mortgage organizations, that verification confirms the platform protects sensitive information with the controls their compliance teams require.
This recognition affirms a belief at the center of PhoenixTeam's work. Innovation and responsibility can advance together. By removing the manual effort that once slowed regulatory change, Phoenix Burst returns time to the teams that need it and positions the mortgage industry to lead rather than react.

featured insights
PhoenixTeam has been named to Inc. Magazine’s 2026 Best Workplaces list, the publication’s annual recognition of companies building cultures that keep and inspire their people. The honor reflects what PhoenixTeam’s own employees say about a workplace where they feel valued, supported, and able to do their best work.
Inc.’s Best Workplaces recognition is earned, not claimed. Companies are evaluated through anonymous employee surveys that measure key aspects of the workplace experience, including engagement, management effectiveness, professional development, work-life balance, and benefits. That commitment to employee well-being is reflected in offerings like fully employer-paid family health care, a benefit that changes the lives of employees and the families who depend on them.
The recognition reflects a culture intentionally built around employee growth, well-being, and connection. Guided by six core values, lifetime learning, impact, entrepreneurialism, service, diversity, and wellness, PhoenixTeam invests in opportunities that help employees thrive.
This award affirms what PhoenixTeam employees experience every day: a workplace worth choosing and a company committed to investing in the people who make its work possible.

featured insights
Who knew a single footnote could create so much noise! I'm heading to American Bankers Association Risk and Compliance Conference (RCC) tomorrow. They asked me to speak on genAI and how it is impacting fair lending. I'll be opening up with what I call "The Infamous Footnote". It's a fairly beefy three sentence paragraph at the bottom of a very recent supervision and regulation letter, SR 26-2 put out by the Board of Governors of the Federal Reserve System.
It's funny, I read this whole document with a critical eye, only to get to the end, puzzled. Nothing in the body of the letter said anything at all about generative AI. With my handy friend Claude, I was then led to the page with The Infamous Footnote (highlighting mine).

Fair lending is the body of law that says credit decisions can't be based on who someone is, only on whether they can repay the loan. It applies to every step of the credit lifecycle. The two main federal statutes are the Equal Credit Opportunity Act (ECOA), which covers all credit, and the Fair Housing Act (FHA), which covers housing-related credit specifically.

To comply with fair lending requirements, you have to design every stage of credit so it doesn't treat protected classes differently and doesn't use "facially neutral" features that act as proxies for protected status. You have to test your actual outcomes for disparities, document why any disparity that exists is justified by business necessity with no less-discriminatory alternative available, and produce specific principal reasons whenever you take adverse action against a consumer. And you have to prove all of that on demand - to examiners, to plaintiffs, to your own board - through inventories, written policies, monitoring records, vendor due diligence, and a paper trail that lets someone reconstruct any single decision from application to outcome.

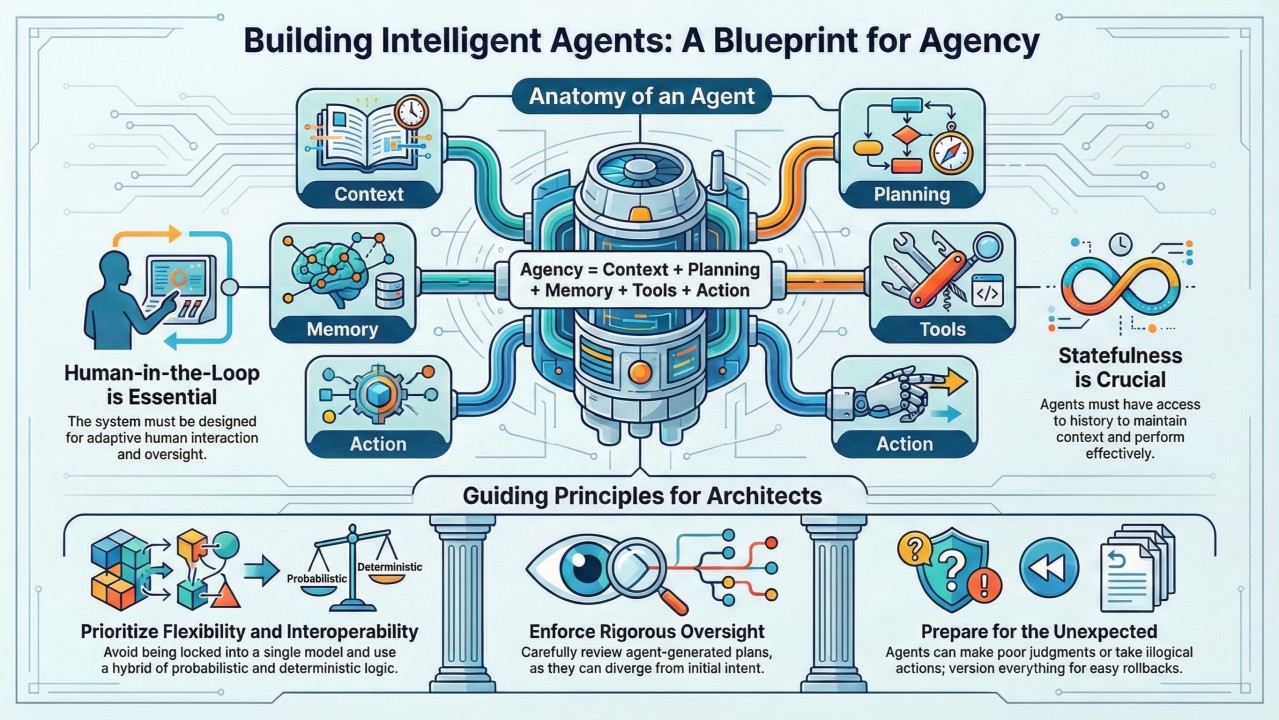
Let's take a generative example and walk it all the way through. ACME mortgage is releasing a generative pre-qualification chatbot on its website in response to customer requests for more self-service options. The goal of the chat both is to engage conversationally with the human, discern the humans intent, and then provide a set of options for which that human might be eligible. Ultimately, the lender could decide to implement this use case in a lot of different ways - with human in the loop, intersecting LLM with more deterministic solutions, there are many options - for our example, let's say the chatbot is autonomous.
The lender would need to design the chatbot so that is does not use things like name or zip code to steer a homeowner into a more expensive product. You need name to pull credit. Zip code is necessary to determine property location and estimate property taxes. Name and zip code are both necessary to pre-qualify a borrower (with credit). Name and zip code are both known "race proxies" in mortgage, variables that looks race-neutral but carry enough racial signal that using it produces the same effect as using race directly. The lender is allowed to use name to pull credit and ZIP code to identify the property and estimate taxes.
What the lender cannot do is let those variables shape the chatbot's product recommendations, rate quotes, or routing — because that's where they would function as race proxies in a way the law treats as discrimination. If the chatbot outputs nonetheless show different outcomes by protected class, the lender's defense is to demonstrate that the design was justified by business necessity and that no less-discriminatory alternative would have served the same need.
In this case, there are two levels of potential for bias to be introduced: (1) the actual application the lender's technology team built to deliver the chatbot to the human, and (2) the underlying foundational model that is discerning intent, potentially deciding request flow, and producing language.
The introduction of generative models like large language models introduces a significant new variable into the testing equation, especially fair lending testing.
When using a large language model at scale, there are two primary roles. The deployer and the developer. The developer is called a foundation model provider - think Open AI with ChatGPT, Anthropic with Claude. They develop the models and make them available for use. YOU as the lender, servicer, regulator, or other mortgage industry actor are the deployer. You are actually giving the model to some set of users to derive benefit for the organization, the homeowners, whomever the target user base is.
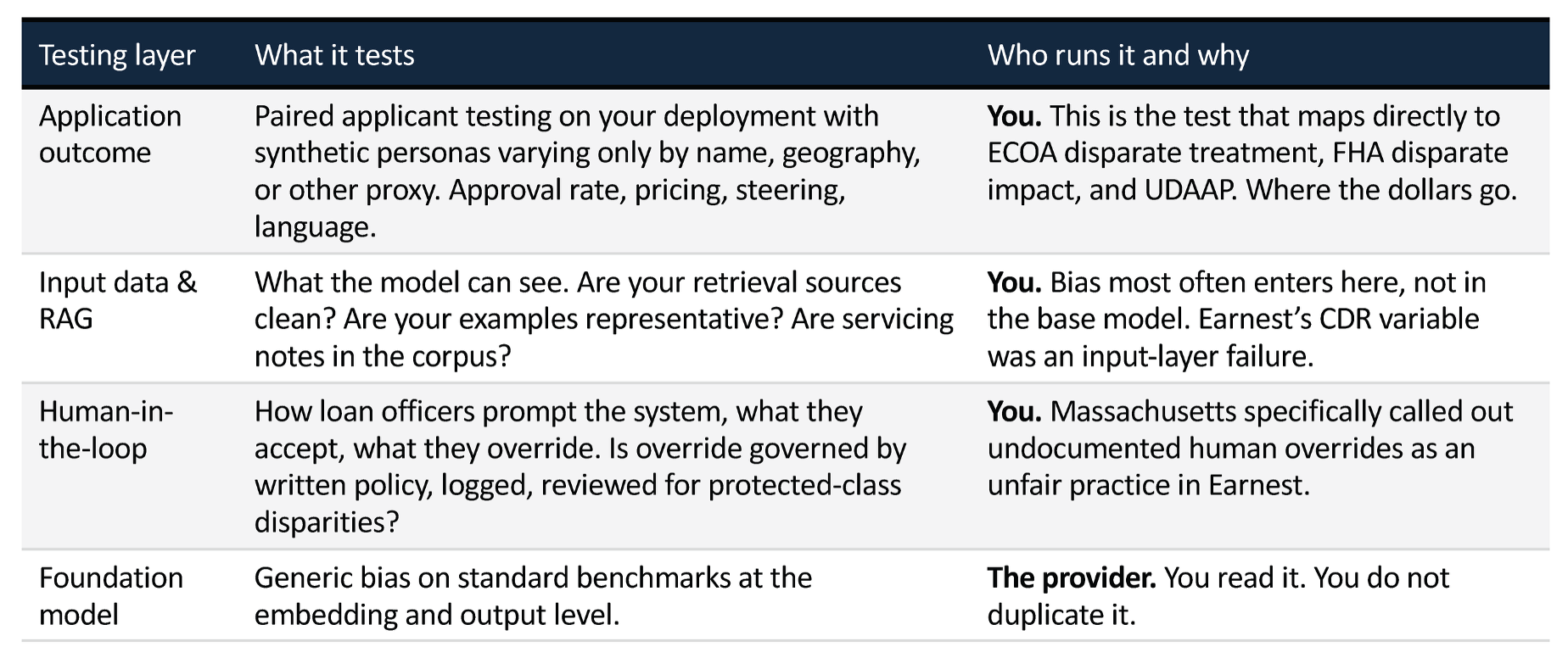
As the deployer, you need to understand what types of bias testing the foundation model provider does - the very common ones are BOLD (Bias in Open-ended Language Generation Dataset) and BBQ (Bias Benchmark for QA). It is good to understand these tests, and understand how (or if) they impact your use cases. That's for you to figure out.
You are solely responsible for fair lending testing on the application, in our example the chatbot. What kind of testing are you obligated to do? This is where the footnote comes in. There is no rulebook for how to test, govern, monitor, or evaluate solutions that incorporate generative solutions. The footnote is really quite unhelpful. First it says generative AI and agentic AI are "out of scope". Then it says your current practices "should guide". And finally it says the principles in the guidance (but not the actual guidance) does apply.
IF, and that's a big if, you decide to implement a pre-qualification chatbot, you should run a standard set of fair lending tests on your chatbot. Follow all the prescribed tests, use all the standard techniques. You should ALSO understand how the generative model is being used in your solution and the extent to which the model capabilities are increasing or decreasing risk. And you should look at what the model providers and any independent benchmarks say about bias testing.
I'll be honest, I don't think an autonomous, generative, pre-qualification chatbot is a good idea right now UNLESS it has a fair amount of determinism in it (so an agentic solution that intersects the intent detection of an LLM with the certainty of a deterministic answering solution).
This is a really challenging topic, with a lot of tentacles. Despite the changes that have happened in the past 12 months, I don't see a responsible way to step back from the traditional practices lenders and servicers have undertaken for fair lending testing. One of the federal requirements has been removed, but the laws are still the laws. The model governance requirements are totally unclear, so we should be cautious in these areas. Be very careful about selecting your use cases. The quadrant chart I provided above gives a good framework, study it carefully and use your best professional (and probably legal) judgment as you make your decisions.
By Tela Mathias, Chief Nerd and Mad Scientist at PhoenixTeam